【工程化】如何查看前端打包体积
webpack-bundle-analyzer
在webpack中,可以使用 webpack-bundle-analyzer分析打包后的体积,首先在源码中我们可以看到具体分析的内容其实为webpack中的stats 对象,通过在webpack compiler 的 done hook 进行处理可以进一步分析出产物结构图。
Stats是什么
那么什么是stats对象呢?引用webpack Stats Data官方解释
When compiling source code with webpack, users can generate a JSON file containing statistics about modules
使用 webpack 编译源代码时,用户可以生成一个包含模块统计数据的 JSON 文件。这些统计信息可用于分析应用程序的依赖关系图并优化编译速度
该文件通常通过以下 CLI 命令生成:
npx webpack --profile --json=compilation-stats.json通过上述解释我们可以了解到,所谓的Stats对象是一串json,为了方便更直观的查看这串json里包含什么元素,我们这里po出一份webpack-bundle-analyzer官方的stats.json文件进行理解。在图中我们可以看到Stats 对象包含以下主要信息:
- 基本构建信息
hash: 构建的唯一标识符version: webpack 版本time: 构建耗时builtAt: 构建时间戳publicPath: 公共路径outputPath: 输出路径
- 资源信息 (assets):每个资源包含名称、大小、所属 chunks 等信息。
- 模块信息 (modules):模块信息包含
identifier: 模块的唯一标识符name: 模块名称size: 模块大小chunks: 所属的 chunk IDreasons: 模块被引入的原因
- 入口点信息 (entrypoints)
产物图详情
了解了stats的基本信息后,我们接着去查看具体的分析报告。当我们查看webpack-bundle-analyzer的产物时,一般会有类似于这种可视化图
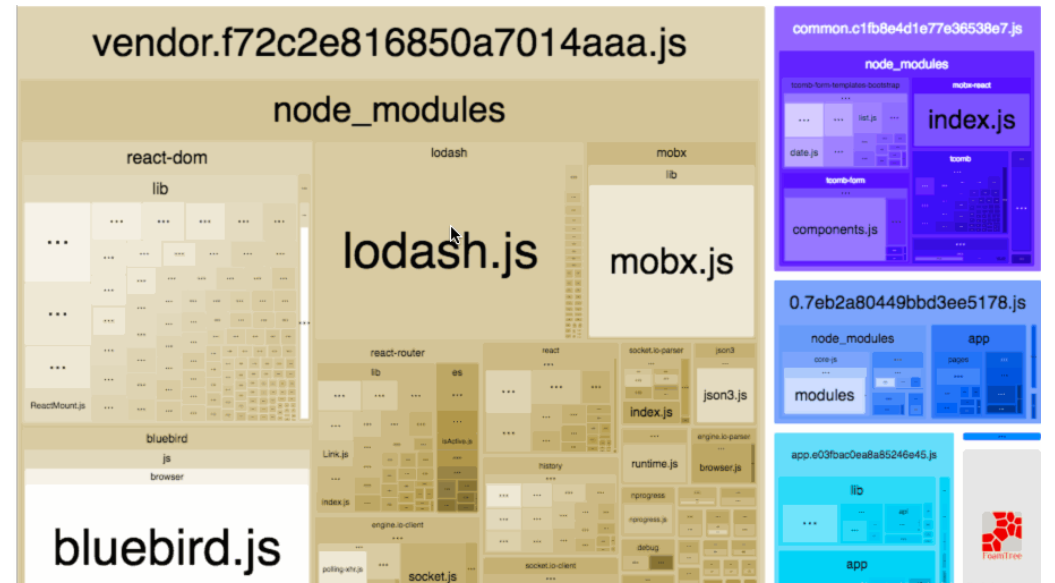
webpack-bundle-analyzer可视化图
同时在查看页面中有三个体积选项,那么这三种选项有什么区别呢,以下将做出解释:
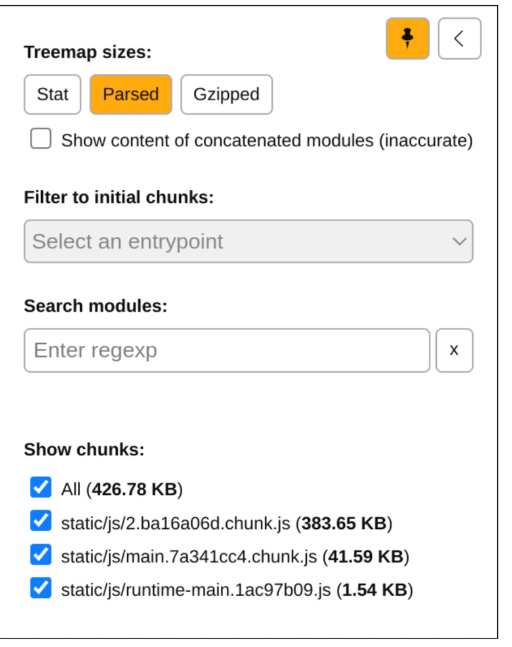
三个体积选项stat、prased、gzip
stat: 每个模块的原始体积(也就是上面提到的json串中的size)parsed: 每个模块经 webpack 实际打包处理之后的体积,比如 terser 压缩、uglify压缩,tree-shaking之后的体积大小gzip: 经 gzip 压缩后的体积在webpack-bundle-analyzer中的代码体现在getGzipSize中
如何配置
在实际项目中,往往通过环境变量 ANALYZE 配置该插件,代码如下,可见bundle-analyze/build.js。
const webpack = require('webpack')
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
// 1. BundleAnalyzerPlugin 是如何工作的?
// 2. Stat、Parsed、Gziped 分别是何意义?
// 3. terserplugin 对此结果有影响吗?
function f1 () {
return webpack({
entry: './index.js',
mode: 'none',
plugins: [
process.env.ANALYZE && new BundleAnalyzerPlugin()
]
})
}
f1().run((err, stat) => {
})在打包时,通过制定环境变量即可分析打包体积
ANALYZE=true npm run build问题引申
上述代码中引申了三个问题,接下来我们分别解答
工作原理
- BundleAnalyzerPlugin 是如何工作的?
我们可以把他的工作拆分为四个流程:
- 插件注册:在 webpack 的
donehook 注册回调,保证在webpack执行完打包之后再去执行BundleAnalyzerPlugin - 数据获取:构建完成后获取 webpack stats 对象
- 数据分析:解析 stats 数据和实际 bundle 文件
- 结果输出:根据配置模式生成服务器、静态报告或 JSON 文件
Gziped 1vs1?
Stat、Parsed、Gziped 分别是何意义?
这个问题上面已经解释过,就不再赘述了,这里贴上一个文章中的观点,去深入了解下Gziped和各个Bundle是否是1v1映射压缩打包的(结论是并不是),详情解释在这里
BTW,为了防止有读者会和我一样很容易搞混什么是bundle、什么是chunk、什么是module、他们和stats.json的关系是什么,这里来理清一下概念
| 名称 | 是什么? | 举个例子 | stats.json 中字段 |
|---|---|---|---|
| Module | 每个文件/模块(JS/TS/CSS 等) | src/App.js、node_modules/react/index.js | modules, 或 chunks[].modules |
| Chunk | Webpack 在打包阶段划分的逻辑分组,包含若干模块 | main chunk, vendor chunk | chunks |
| Bundle(= Asset) | Webpack 输出的实际文件,是 chunk 最终生成的结果(可能是 gzip 压缩的对象) | main.js, vendor.js | assets |
stats.json 只是描述打包结果的元数据
那么在理清概念之后我们再回到为什么不是一对一映射的问题,引用上面文章中的原文,以及相关github讨论
Thus the gzip size shows you the size after minification and gzip, but it isn't a 1-to-1 mapping with the actual file sizes as gzipping each module separately yields less "wins" in terms of compression as the separate sources have less opportunities for gzip to compress together
其中不太好理解的是这句话"in terms of compression as the separate sources have less opportunities for gzip to compress together"那么为什么会存在单独解析无法便于gzip压缩的情况呢,是因为gzip 是一种基于重复模式进行压缩的算法。如果你把所有模块合并成一个大的 bundle 去 gzip(即实际生产构建行为),gzip 可以利用更多重复模式(比如重复变量名、函数结构、字符串等),压缩率更高。但如果你逐个模块单独压缩,因为重复性被分散,就很难获得同样的压缩比,这就叫 “less wins”。
同样的在这个PR中也有这样一条回复,也就是说1v1压缩和整个合并压缩都有,但是1v1会存在估算的情况,因为他是基于stats.json 中的元数据关系去估算具体压缩大小,所以与实际压缩大小可能会存在误差。整个合并则不会这种问题,结果会更准确。
terserplugin配置
3.terserplugin对此结果有影响吗
了解Stat、Parsed、Gziped三者的概念后,我们可以知道terserPlugin作用原理主要是降低parsed和gziped的体积大小
具体使用可以在webpack.config.js中查看,如下
optimization: {
minimize: !isDev,
minimizer: [
new TerserPlugin({
parallel: true,
terserOptions: {
output: {
comments: /copyright/iu
},
safari10: true
}
})
]
},rollup-plugin-visualizer
如何配置
在vite项目中我们也可以配置rollup-plugin-visualizer来分析前端打包体积,具体配置如下:
import { defineConfig } from "vite";
import { visualizer } from "rollup-plugin-visualizer";
export default defineConfig({
plugins: [
visualizer({
filename: "./stats.html", // 明确指定输出文件名
open: true, // 构建后自动打开
brotliSize: true,// 开启brotli压缩
}),
],
build: {
minify: "terser",
terserOptions: {
compress: {
drop_console: true,
drop_debugger: true,
},
},
rollupOptions: {
output: {
manualChunks: {
react: ["react", "react-dom"],
lodash: ['lodash-es'], // 单独分块打包 lodash-es
// 可按需添加更多分块
},
},
},
sourcemap: false,
},
resolve: {
alias: {
'lodash': 'lodash-es', // 将 lodash 指向 lodash-es
},
},
optimizeDeps: {
include: [
"react",
"react-dom",
"axios",
"lodash-es/cloneDeep" // 添加 cloneDeep 到预构建
],
},
});相关的可视化图为
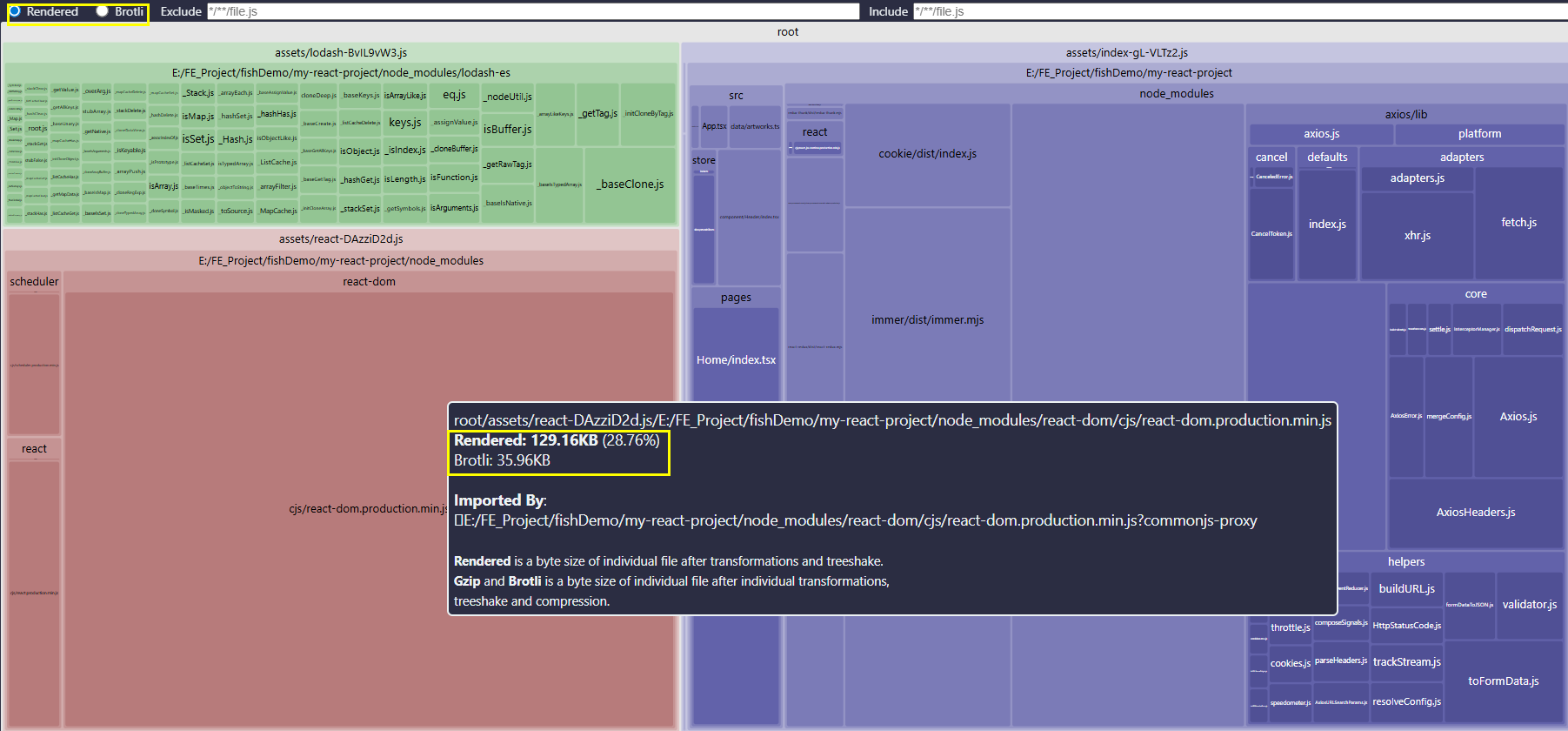
rollup-plugin-visualizer可视化图
顺便一提,图示中我们采用的压缩方式并不是gzip,而是brotli他是一种比gzip更高效的压缩算法,目前compression-webpack-plugin和vite-plugin-compression都已支持直接生成.br类型的压缩文件。同时这里也po出一份webpack中配置brotli压缩生成文件的方式:
const { BundleAnalyzerPlugin } = require('webpack-bundle-analyzer')
const CompressionPlugin = require('compression-webpack-plugin')
const zlib = require('zlib')
module.exports = {
plugins: [
// Brotli 压缩生成br文件
new CompressionPlugin({
filename: '[path][base].br',
algorithm: 'brotliCompress',
test: /\.(js|css|html|svg)$/,
compressionOptions: {
params: {
[zlib.constants.BROTLI_PARAM_QUALITY]: 11, // 最大压缩
},
},
threshold: 10240,
minRatio: 0.8,
}),
// Gzip 压缩(可选)
new CompressionPlugin({
filename: '[path][base].gz',
algorithm: 'gzip',
test: /\.(js|css|html|svg)$/,
threshold: 10240,
minRatio: 0.8,
}),
// 分析报告
new BundleAnalyzerPlugin({
analyzerMode: 'static', // 生成静态 HTML 文件
openAnalyzer: true,
generateStatsFile: true,
statsFilename: 'stats.json',
// 启用 gzip 大小计算分析包体积
defaultSizes: 'gzip'
}),
],
}工作原理
那么,和剖析webpack-bundle-analyzer的产物一样,我们这里也来探讨一下rollup-plugin-visualizer是如何进行可视化的。和webpack的打包产物一样,roll打包的产物也有bundle(asset)、chunk、module。rollup-plugin-visualizer 通过 Rollup 的 generateBundle 钩子获取打包产物信息,然后将模块数据转换为可视化图表。其工作流程大致分为3个模块:
1.Bundle 分析
插件遍历 OutputBundle 中的每个 chunk,提取模块信息
2.模块大小计算
支持多种大小计算方式:
- 原始大小:直接从 bundle 模块获取
- Gzip 压缩大小:可选启用
- Brotli 压缩大小:可选启用
- Sourcemap 模式:基于源码映射计算更精确的大小
3.树形结构构建
使用 buildTree 函数将模块数据组织成层次化的树形结构, 其数据结构:即最终生成的 VisualizerData 包含:
tree: 模块层次结构nodeParts: 模块大小信息nodeMetas: 模块元数据env: 环境信息(Rollup 版本等)options: 配置选项
Lighthouse devtool
同样我们在chorme devtool中也有相关面板可以查看bundles的打包情况,还可以查看未使用代码的数量等
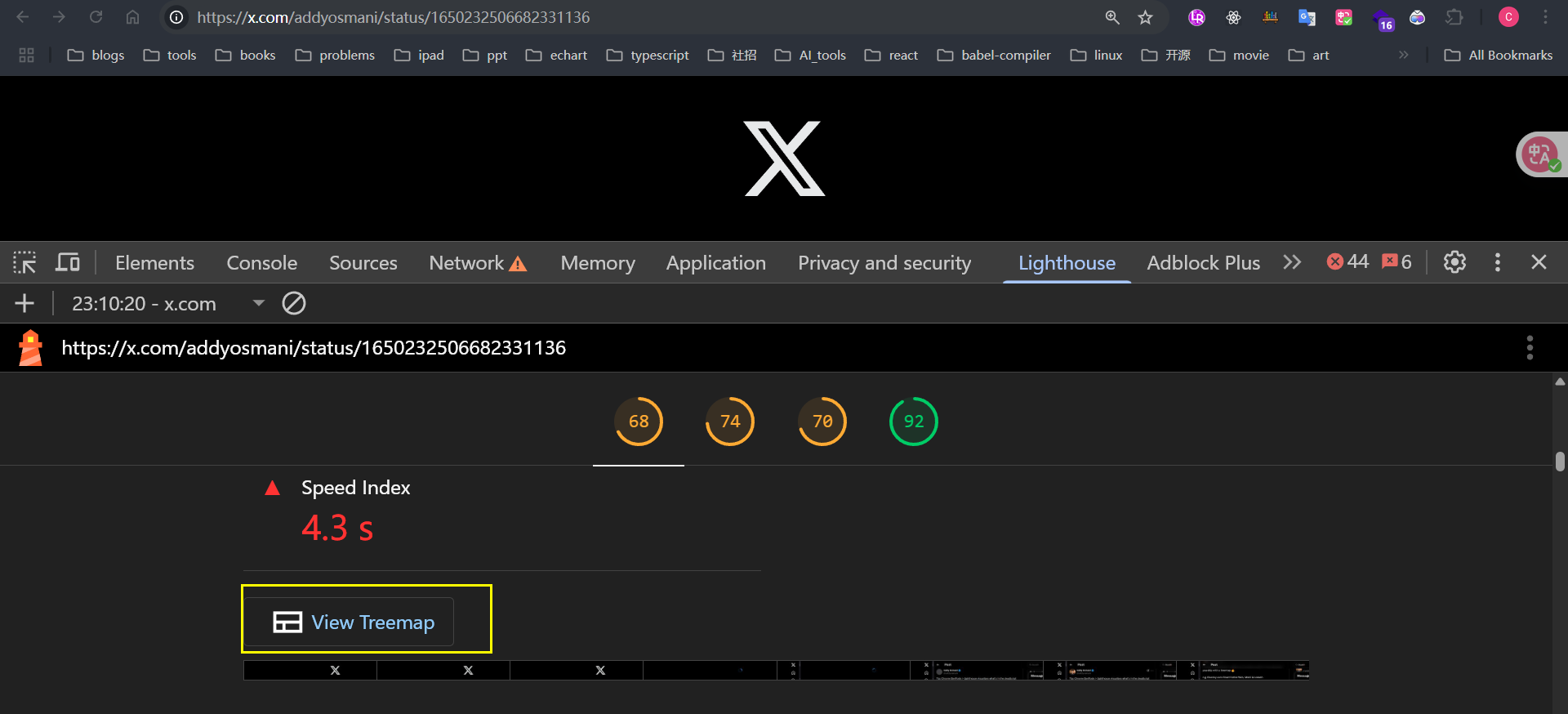
chorme devtool入口
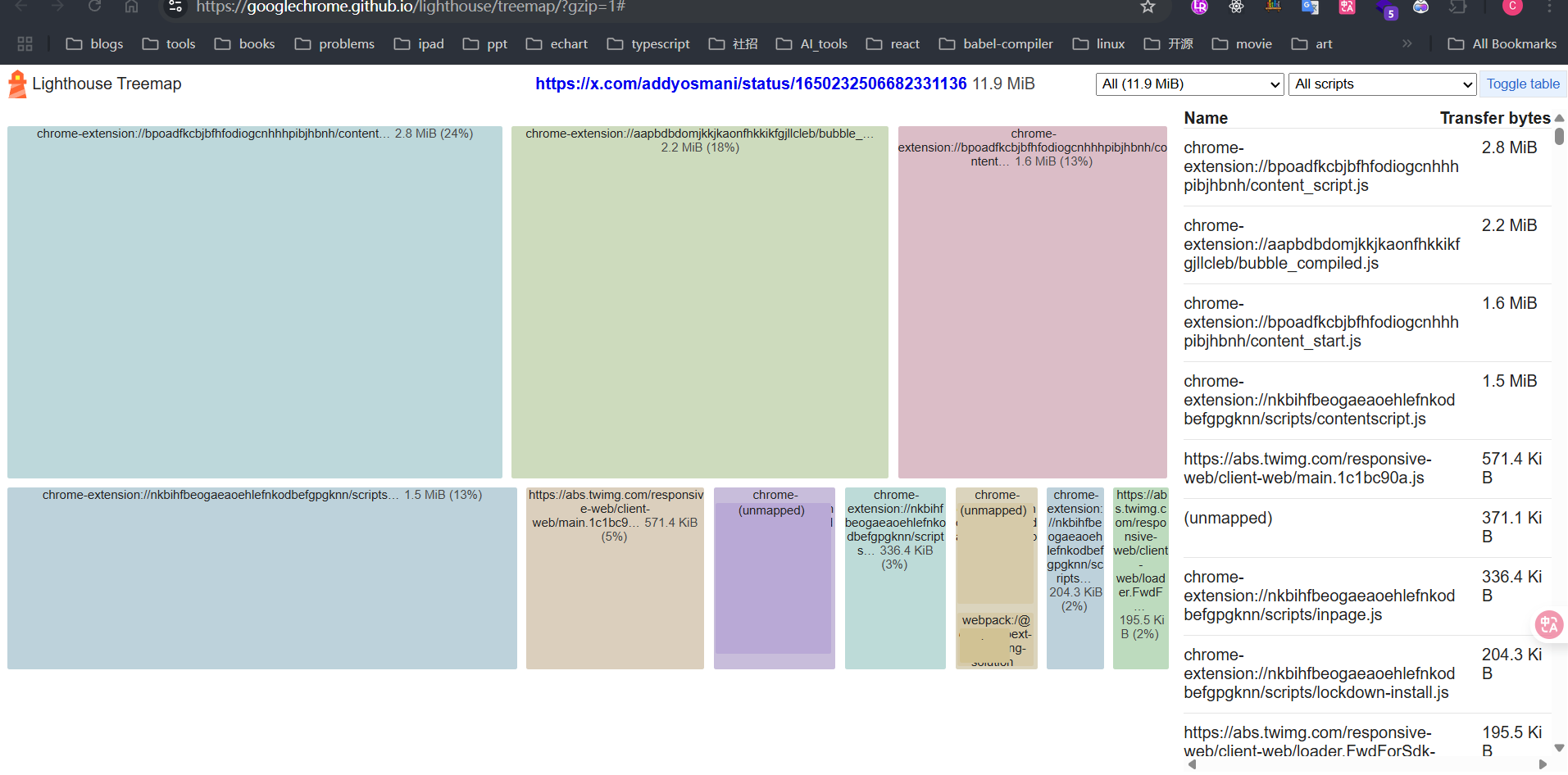
lighthouse treemap
ref参考